

The dramatic expansion in computing power and the huge amounts of data generated within organizations have led to an increase in new methods to identify patterns and trends among large datasets. Chief among these are data mining and predictive analytics (also called machine-learning processes)—cross-disciplinary approaches consisting of advanced computational statistics that are able to recognize patterns and predict trends from the data.
In unconventional reservoirs, sweet spot recognition is essential to reducing uncertainty, high-grading acreage and improving field economics. Identifying sweet spots, however, requires a detailed understanding of complex reservoir properties and how these influence the productivity of the wells. Inevitably, this involves large amounts of data, from the static (horizons and faults)
through to lithological properties and organic content.
Classical approaches to mapping out and predicting reservoir behavior tend to combine geophysics, geology and reservoir engineering to estimate reservoir properties, both at local and regional scales. This integrated approach can be improved even further thanks to predictive analytics specifically designed to get the best out of large input datasets.
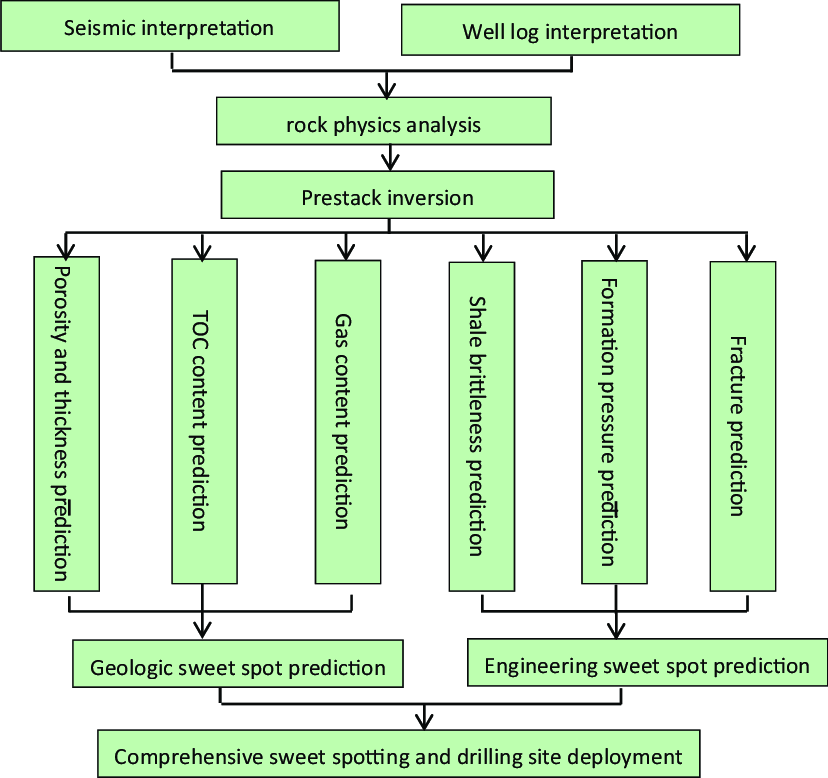
The sweet spot prediction workflow consists of the analysis of measurements that classify samples into specific groups characterized by predictive patterns. The goal of the workflow is to predict the potential interest of areas that are located far from the wells by identifying sets of indicators that show clear trends that correlate with the best producing wells. These most relevant properties can be used as a training pattern, and the classification of samples can be expanded to the entire target region by exploring the nearest neighborhood of each sample to classify all points according to their similarities.
Relevant datasets can be log measurements, 3-D grid properties and seismic data. These data are integrated into one geomodel that can be divided into sub-areas depending on the global size of the studied area. Production data also are valuable to the workflow, but their variations in time can sometimes make their integration complex. To avoid this, it can be useful to deal with the data by different stages. Production data also can be translated into well properties, reflecting the productivity of each well across time and depth.
As part of the workflow, all well data are first quality-controlled to ensure that outliers don’t create unnecessary noise. The grid created from structural maps and limiting the reservoir areas is then populated with properties derived from both well data and seismic attributes. Such properties include fracture density, rock brittleness, and gas saturation or thickness maps.
The next stage involves defining the training set and applying the classification algorithm. The classification process is based on user-defined selection, and specialized analytical tools can be used to determine a reduced but optimal number of explanatory variables, including, for example, fracture density, total organic carbon and shale thickness. Working with a low number of explanatory variables makes the algorithm more robust and reduces the computational cost without sacrificing precision. Through the identification of similar patterns in areas with low well control, sweet-spot likelihood maps can then be generated.
After the algorithm is run, the classification of the area of interest can be separated into two different classes: a potential sweet spot vs. a nonsweet spot. The probability of the class to be correctly computed is then calculated, providing indications on the quality of the prediction. This is particularly important during risk assessment phases, in which several scenarios can be envisaged as a prelude to decision-making.
Through a step-by-step integrated and multidisciplinary workflow and the use of predictive analytic tools and machine-learning algorithms, datasets can be generated from unconventional reservoirs. They can be mined to their maximum potential to identify sweet spots and deliver improved decision-making on where to drill, what production strategies to adopt and how to unlock the value of operator assets. In this way the relevance of geomodels can be enforced, classification algorithms can be used to capture complex interplays and predictive analytics can optimize unconventional reservoir investments.